In this post, I will argue against the view that we should trust academic experts. By “trust academic experts” I mean endorsing the following two propositions:
- Academics endorsing a proposition is strong evidence that the proposition is true or at least that the proposition is maximally warranted by the available evidence.
- The fact that an argument is being made by a non-academic is strong enough evidence against the soundness of the argument to justify ignoring the argument.
In this post, I will exempt from my arguments academic experts in physics, chemistry, and closely related fields (e.g. engineering).
The question of whether to trust academic experts is a particular instance of a broader set of questions about which, if any, institutions we should trust to give us accurate knowledge about the world. For most of history, the institutions people relied on for such knowledge were at least partly religious in nature. People who trust academics in the sense that I’ve defined necessarily do not trust religious institutions in the same way. Generally, such people also think that while it may have been understandable psychologically, it was never rational to trust such institutions because said institutions did not employ the methodologies necessary to form warranted beliefs about the empirical world. Such people would also generally agree that various so called institutions which have professed to be scientific were actually not rational to trust. Obvious examples of this include anthropology in Nazi Germany, evolutionary biology in the Soviet Union, phrenology, etc. If all this is agreed upon, then it clearly follows that institutions which people are socialized to trust have normally not actually been rational to trust as a source of warranted beliefs.
Because virtually all the sciences have been heavily revised with time and the beliefs supported by non-scientific institutions are now widely regarded as false, it is also clearly true that beliefs endorsed by these sorts of institutions have usually been false.
These considerations lead us to the view that the probability of any randomly selected institution that people have been socialized to look to for knowledge is normally not worth trusting. Given this, we should only accept that an institution is worth trusting in light of positive arguments that this is the case. Our default assumption should be that it is untrustworthy and the burden of proof should be placed on those claiming otherwise.
While I think this default assumption is necessary to avoid being the sort of person who would have fallen victim to countless false authorities of the past, even if this default assumption is not accepted the data presented in this article constitutes significant positive evidence against trusting academia as an institution.
Generally speaking, people who trust academic experts do not do so because of specific arguments which justify this trust. Rather, it seems obvious that such trust is generally the result of people being told to trust academics by various authorities, not the least of which are academics themselves who people are made to interact with extensively in college. Because college consists (in part) of people learning from academics and being tested to see that they have memorized the views of professors, it would be surprising if it didn’t lead to people placing some degree of trust in academics. Moreover, when learning how to “think critically” people are often taught to vet sources for recency, a lack of funding from non-academic sources, and having passed peer review, which is to say that they are taught to check that sources are at least to some degree endorsed by the modern manifestation of the academic community.
Of course, the fact that most people don’t come to trust academics in response to explicit arguments does not mean no such arguments exist. It is fairly easy to imagine several arguments that are implicit, and sometimes made explicit, which underlie people’s trust in academics.
Academics Can’t Predict Things
For instance, it is easy to imagine someone arguing that an academic credential is a valid way of evidencing that someone has read a good deal about a subject which has given them a greater understanding of the world than someone is likely to possess who lacks such a credential. This argument is undermined by research on the ability of academics to predict events in the real world that are relevant to their domain of expertise.
(To be clear, I am in no way denying that academics learn many things while becoming an academic. What this research undermines is the view that they learn things that interested lay people don’t also learn which are true and help them to make better predictions reflecting a genuine understanding of the real world.)
For instance, Einhorn (1973) examined three experienced pathologists (and a forth judge which was the average of the three) who assessed the severity of cancer in 193 patients based on 5 point scales of various symptoms that they deemed important. Severity, if accurately assessed, should significantly negatively correlate with survival time, but this was not true for any of the pathologists. In fact, the severity rating of the average of the three doctors (judge 4) had a non-significant and positive correlation with survival time.

Moreover, using the same symptom ratings as the doctors a computer algorithm was able to significantly predict survival rates. This implies that the doctors had useful information available to them but combined and weighed that information in such a way that they failed to utilize any of its predictive validity.

Even when using all the judges ratings at once, they added little to the predictive validity of the model.

Similarly, Szalanski et al. (1981) had 9 physicians estimate the probability of of pneumonia developing in 1,531 patients. The main result suggests that the doctors were only marginally more accurate than guessing at random would have been.

Lee et al. (1986) had doctors predict the probability that patients with heart disease would survive over the next one and three year periods. Doctors assigned a roughly equal probability to patients who ended up living and those who ended up dying.

Thus, Doctors seem pretty bad at predicting things like whether you have a disease, how severe your disease is, and whether you will live for the next few years given your disease.
One might object that while doctors are trained in academia they are not generally academics. On these grounds, we might think the ability of epidemiologists to predict the fatality rates of diseases would be more informative. Well, swine flue was estimated to have a fatality rate between 0.1% and 5.1% and ended up having a fatality rate of .02% meaning they experts were off by at least a factor of 5 (Oke et al., 2020). During the SARS outbreak of 2003 experts initially estimated it to have a fatality rate of roughly 4% but it was eventually shown to have a mortality rate of roughly 10% (Ross, 2003; Mahase, 2020). Similarly, the fatality rate estimates for the Ebola outbreak in 2013 had to be revised from 49% to 70% (Mackay et al., 2014). So epidemiologists are pretty bad at predicting how bad a disease is going to be.
Turning to economics and finance, Bordalo et al. (2017) analyzed the returns to stocks after sorting them by long term growth forecasts given by financial analysts. The highest returning stocks were those in the bottom 10% of projected growth while the weakest returns were seen among stocks in the top 10% of expected growth, suggesting that one could make significant gains by treating financial experts as anti-experts (people with views that are negatively correlated with reality rather than merely uncorrelated with reality).

Braun et al. (1992) reported on 40 professional economic forecasters who were surveyed yearly between 1968 and 1988. They could sort of predict recessions that were just about to happen but if the time horizon was more than a couple months in the future their predictive accuracy quickly fell to something similar to what we’d expect if they were guessing randomly.



Tetlock (2004) had a sample of 284 experts make 27,451 predictions between 1988 and 2003 about the economy, political elections, and international relations events. Tetlock found that experts and generally knowledgeable non-experts (dilettantes) had similar forecasting abilities, and both were only moderately better than undergraduate students. 
As can be seen, the difference in ability between groups was especially small for events that had probabilities between 30% and 70% of occurring.
Importantly, measures of academic status, self rated expertise, access to classified information, etc., were unrelated to forecasting accuracy. 
This suggests that the training people went through to acquire academic credentials was not the reason experts had moderately better predictive ability than undergraduate students. Of course, the fact that generally knowledgeable non-experts were roughly as predictive as experts suggests this even more directly.
It’s also worth noting that simple computer algorithms were able to out predict experts by a quite large margin. So these sorts of events are quite predictable in principle.

DellaVigna et al. (2016) compared the ability of experts (behavioral economists and relevant psychologists) and non-experts to predict the results of behavioral experiments aimed at changing the degree of effort people put into various tasks.

When accuracy was measured as mean absolute error, the ranking of accuracy was experts > phd students > undergrad students > MBA students> MTurk Workers when considering individual forecasts. The differences between experts and students was small.
When considering group forecasts, the ranking of accuracy was undergrad students > phd students > academic experts > MBA students > Mturk workers.
When accuracy was measured as the correlation between predicted and observed effort rather than mean absolute error, the ranking was phd students > undergrads > experts > Mturk workers > MBA students when considering individual forecasts and Mturk workers > undergrads > phd students > experts = MBA students.
In no case was the rank order of prediction what we would predict if we thought academia was teaching people knowledge that increased their understanding of the real world.
Turning to lawyers, Ruger et al. (2004) found that a sample of legal experts was only able to predict the results of supreme court cases at a rate modestly better than chance. Computer models were far more accurate.

Moreover, the accuracy of these legal experts was largely driven by private attorneys. Academics only had an accuracy rate of 53%, scarcely better than random chance.

With respect to psychologists, it’s been shown that only 16% of developmental psychologists were able to correctly predict that self control had increased among children over the last 50 years.
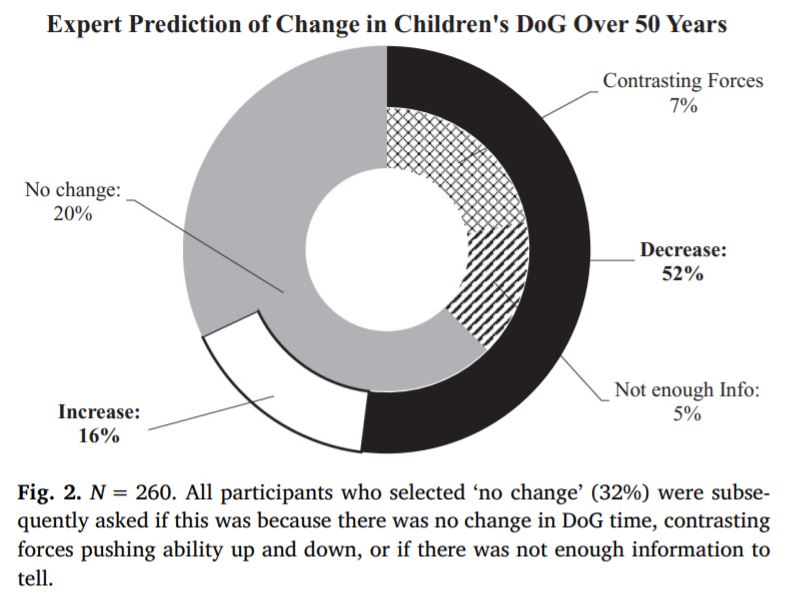
Hutcherson et al. (2021) asked a range of social scientists to predict how the COVID-19 pandemic was going to impact things social scientists study (e.g. depression rates, political polarization, etc.). Said social scientists (n=717) were no more accurate than lay people (n=394) in their predictions.
In contrast to these findings, Mandel et al. (2014) looked at the accuracy of 1,514 strategic intelligence forecasts. The average deviation between the objective and predicted probability of events was 13%.

This degree of calibration is higher than what we’ve seen in other work. Unfortunately, there was no non-expert control group, so it is hard to judge how impressive this result really is. It should also be noted that these were short term predictions (59% under 6 months and 96% under one year) which probably increases accuracy (Tetlock et al., 2014).
This research literature is imperfect. The samples are limited and we might like to test other sorts of predictions that have not been studied. But as already stated, the burden of proof should be on those affirming the validity of academic experts, not on skeptics, and the totality of the evidence we have suggests that academic experts in fields like finance, economics, psychology, law, and medicine, either can’t predict reality well at all, or can’t predict reality significantly better than interested non-experts.
Academics Don’t Understand Statistics
It is also easy to imagine someone arguing that we should trust academics because academic credentials show that someone has the relevant quantitative training needed to understand data that is relevant to empirical questions.
This argument has already been undermined by the low predictive validity of academic experts. If they do possess a sophisticated understanding of statistics, it has evidently failed to lead to them having a strong understanding of how the real world works.
This argument is further undermined by the fact that we have good reason to think that academic experts are usually too statistically illiterate to be able to interpret and conduct new empirical research in a responsible way.
| Citation | Sample | Finding |
| Lyu et al. (2019) | 759 Professors and students | More than 85% of students and professors from the following fields endorsed at least one misinterpretation of p-values and/or confidence intervals: science, engineering, medicine, economics, management, psychology, math/statistics. |
| Zuckerman et al. (1993) | 551 psychologists | When given a quiz concerning common statistical issues dealt with in psychological research, psychologists on average answered 55% of questions correctly. |
| Koekstra et al. (2014) | 118 psychology researchers | At least one of six misinterpretations of confidence intervals were endorsed by 97% of psychologists |
| Haller et al. (2002) | 113 Psychology professors and students | At least one of six misinterpretations of a t-test were endorsed by 80% of psychologists teaching statistics (mean = 1.9), 89.7% of psychologists not teaching statistics (mean = 2.0), and 100% of psychology students (mean = 2.5). |
| Oakes (1986) | 70 Psychology professors | At least one of six misinterpretations of a t-test were endorsed by 97% of psychologists. |
| McShane et al. (2015) | 75 Epidemiologists | When told about a cancer intervention in which group A lived longer than group B, 89% of epidemiologists denied that, “speaking only of the subjects who took part in this particular study”, participants in group A lived longer than participants in group B when the p value of the difference exceeded .05. |
| McShane et al. (2015) | 261 Epidemiologists | When told about an intervention in which the rate of disease recovery was higher of those taking Drug A than for those taking Drug B, 79% of epidemiologists denied that a person was probably more likely to recover if assigned drug A rather than drug B when the p value of the difference between the recovery rates exceeded .05. |
| McShane et al. (2016) | 117 Statisticians | When told about a cancer intervention in which group A lived longer than group B, roughly 50% of statisticians denied that, “speaking only of the subjects who took part in this particular study”, participants in group A lived longer than participants in group B when the p value of the difference exceeded .05. |
| McShane et al. (2016) | 140 Statisticians | When told about an intervention in which the rate of disease recovery was higher of those taking Drug A than for those taking Drug B, 84% of statisticians denied that a person was probably more likely to recover if assigned drug A rather than drug B when the p value of the difference between the recovery rates exceeded .05. |
| Lecoutre et al. (2003) | 25 private sector statisticians and 20 psychologists | In a drug trial resulting in a large effect size but an insignificant p value, 52% of statisticians and 65% of psychologists thought no conclusion could be drawn about the drug’s efficacy, 36% of statisticians and 35% of psychologists thought the drug was ineffective, and 12% of statisticians and 0% of psychologists thought the drug was effective. |
As can be seen, numerous studies have shown that the vast majority of academics working in psychology, epidemiology, and even the hard sciences, don’t understand basic statistical concepts like p values, confidence intervals, and t tests, and fail simple applied questions as well.
Similarly, reviews of papers published in medical journals typically find that the vast majority of papers commit statistical errors than render them methodologically unacceptable.

This statistical illiteracy of academics likely partly explains why it is that papers in many fields have replication rates and levels of statistical power below 50%.
| Citation | Field | Replication Rate |
| Soto (2019) | Differential Psychology | 87% |
| Cova et al. (2019) | Experimental Philosophy | 70% |
| Camerer et al. (2016) | Economics | 61% |
| OSC (2015) | Social Psychology | 25% |
| OSC (2015) | Cognitive Psychology | 50% |
| Prinz (2011) | Pharmacology | 21% |
| Begeley and Ellis (2012) | Oncology | 11% |
| Neuroskeptic (2014) | Neuroscience | 6% |
What this suggests is that, on average, a study testing a true hypothesis will probably not produce a significant result and so we can’t make much of a null result. At the same time, a study that does find a significant result probably won’t replicate, meaning we can’t make much of a positive result either.
| Citation | Discipline | Mean / Median Power |
| Button et al. (2013) | Neuroscience | 21% |
| Brain Imaging | 8% | |
| Smaldino and McElreath (2016) | Social and Behavioral Sciences | 24% |
| Szucs and Ioannidis (2017) | Cognitive Neuroscience | 14% |
| Psychology | 23% | |
| Medical | 23% | |
| Mallet et al (2017) | Breast Cancer | 16% |
| Glaucoma | 11% | |
| Rheumatoid Arthritis | 19% | |
| Alzheimer’s | 9% | |
| Epilepsy | 24% | |
| MS | 24% | |
| Parkinson’s | 27% | |
| Lortie-Forgues and Inglis (2019) | Education | 23% |
| Nuijten et al (2018) | Intelligence | 49% |
| Intelligence – Group Differences | 57% |
I suspect that this is the state of things partly because academics don’t understand well or care much about statistics, but that is just speculation on my part. I can say with more certainty that this state of affairs increases the degree of statistical sophistication required in order to responsibly consume research, and this should be concerning given that most academics don’t fully understand the concepts taught in freshmen level statistics courses.
Peer Review
Someone might also argue that academic research can be trusted because it must pass through peer review to be published.
This argument pre-supposes that the academics doing the peer review are valid experts and so cannot be a compelling argument for trusting academics more than we would trust a non academic who has their arguments reviewed by other non-academics before presenting them to you.
Research on the peer review process makes this justification even more implausible. Academic journals and conferences have accepted articles intended as jokes and meaningless articles auto-generated by computer programs at alarming rates. When effort is put into fake articles so that they should seem plausible to non-experts but which contain high-school level chemistry errors, the acceptance rate even in hard science journals is over 50%.
| Citation | Description |
| Labbe et al. (2013) | Auto generated articles submitted to academic computer science bibliographies had acceptance rates ranging from 13.3% to 28% due to them appearing at academic conferences. |
| Murphy (2009) | The British Medical Journal published an article on a false disease, “cello scrotum”, despite the authors of the paper expecting the journal to realize the disease wasn’t even possible. |
| Beauchamp (2018) | Absurd fake papers were published in several “grievance study” journals (fields that focus on the victimization of various groups) and one paper was even nominated for an award. |
| Bohannon (2013) | The majority (52%) of 304 versions of a fake paper containing basic chemistry errors were accepted into various journals of pharmacology, biology, and chemistry, including journals published by Elsevier and Sage. |
Moreover, meta-analyses find that peer reviewer’s inter-rater agreement is only slightly better than what would be expected given random chance (Bornmann et al., 2013). This fact alone makes it hard to take seriously the idea that peer review is even remotely accurately screening for the quality of research or ideas.
Further still, research shows that peer reviewers rate research as being of higher quality when the results of the research agrees with their prior beliefs (Mahoney, 1977; Koehler, 1993). Thus, scientists seem to exhibit the same sorts of cognitive biases that lay people do and as a result peer review serves to reinforce the status quo rather and inhibit innovation.
The Achievements of Science
Another argument someone might make is that the historical achievements of science give us good reason to accept the authority of academics. Historically, the rise of scientific authority can no doubt be explained partly by the fact that the physical sciences provided many answers to questions which previous methodologies (e.g. religion) had either failed to answer correctly or had failed to answer at all.
However, the achievements of these physical sciences cannot be validly used to justify trust in social sciences. The differences between these two sets of sciences is immediately suggested by the fact that the social sciences largely lack the sort of impressive achievements the physical sciences have accomplished.
Moreover, there is a clear difference between these sets of fields in that one is directly tested against reality in a way the other is not. If the experts were wrong about how to make computers, cars, and airplanes, we’d find out immediately.
There’s not analogous test for most other “sciences”. Determining whether a theory from sociology, or psychology, or economics, etc., made a false prediction is much harder than is telling whether someone can make a computer. And if a theory does make a false prediction the theory is often retained because such predictions are probabilistic in nature. If a false prediction is made about the real world, as opposed to an experiment, then this can always be reconciled with a theory by noting that the real world is complicated and unexpected things are bound to happen. If a theory makes a false prediction in the context of an experiment, the theory can be retained because, as we’ve seen, most experiments are statistically inadequate to validly test a hypothesis. Perhaps most importantly, the public aren’t qualified or motivated to keep track of any of this and so we have to rely on scientists to police themselves. By contrast, if the experts were wrong about how to make computers the public would quickly and effortlessly find out.
This difference in incentive structure may explain how it is that so many academic fields are filled with experts who can’t make valid predictions on the basis of their academic training.
A further reason for doubting this argument stems from the fact that scientific progress is largely attributable to a small minority of scientists. A quantitative version of this observation was made famous by Alfred Lotka who, in the 1920s, noted that roughly 60% of physical scientists have only ever published one article.

Other work in physics found that nearly half of scientific citations went to just 200 physicists, and that the top 10% of scientists were roughly three times as productive as the bottom 50% (Cole and Cole, 1972; Dennis, 1955).
Research across numerous fields has also shown that a small proportion of academic articles account for more than 80% of citations. This was especially true in the early 20th century, when less than 10% of articles accounted for 80% of citations.

Even today, in most fields it takes years for the average article to get even a single citation. In the humanities, less than 20% of produced papers are ever cited by anyone.

This can also be seen by looking at how academic experts (both individual experts and groups of experts) themselves rank the relative importance of individuals across various methods, including having people give direct ratings, looking at how frequently individuals are cited, or even analyzing the space each person is given in topic-specific encyclopedias. Such methods produce reliability coefficients of .86 for art and .94 for both philosophy and science. Even when comparing sources from different nations, including comparisons between western and non-western sources, there is a remarkable degree of agreement (Eysenck, 1995; Murray, 2003).
Charles Murray’s database on significant contributors to science up to the year 1950 confirms Lotka’s observation. Unfortunately, Murray doesn’t actually provide a chart corresponding to this observation for science, but he says that the chart he gives for art roughly looks the same as the ones he generated for the sciences.

This data relates to trust in academic experts in the following way: if most scientists don’t significantly contribute to science then academic training usually doesn’t lead to the ability to significantly contribute to science. Thus, whatever trust should be given to the people who are responsible for the significant achievements of science should not be given to most academics.
Political Bias
It’s also worth mentioning briefly that academics are far more leftist than is the general population and so we should expect that academia will exhibit a pro-left bias as well until we have some positive evidence indicating that, unlike lay people, academics have freed themselves from the influence of political biases.



Fraud
Finally, I’ll note that the self reported and peer reported data on the rates of fraud and malpractice in science doesn’t inspire confidence, especially given that such rates surely under-estimate the true rates of fraud and malpractice: “A pooled weighted average of 1.97% (N = 7, 95%CI: 0.86–4.45) of scientists admitted to have fabricated, falsified or modified data or results at least once –a serious form of misconduct by any standard– and up to 33.7% admitted other questionable research practices. In surveys asking about the behavior of colleagues, admission rates were 14.12% (N = 12, 95% CI: 9.91–19.72) for falsification, and up to 72% for other questionable research practices.” – Fanelli (2009)
Conclusion
In conclusion, I don’t think we have good reasons for trusting academics in the way defined at the beginning of the post. Of course, this does not mean we should dismiss things said by academics. Nor does it mean that there aren’t sources of information less worthy of trust than academics are.
What it does mean is that we can’t rely on academia to do our reasoning for us and we shouldn’t reject information just because it is coming from somewhere other than academia. The difference in knowledge and skill between academics and interested lay people is simply not great enough to justify such a norm, especially when we have reason other than academic credentials to believe that someone has made an effort to seriously study a topic.
The data reviewed here should also highlight the fact that people are often shockingly ignorant despite them making an effort not to be. Generally speaking, people under-estimate how uncertain they should be in their beliefs about academic matters whether they are placing trust in academics or not.

Hey, thank you so much for posting this. I’ve enjoyed being subscribed to your blog, and it motivates me to get a better grasp of statistics myself.
These findings are so relevant right now and always, as I have been hearing many people lately expressing confidence in their beliefs because they “trust the experts.” I regret not asking which experts, in particular, when this phrase is mentioned, because I would like to remind them that not all experts in a given field even agree with each other, and scientists are not unanimous. That disagreeing experts exist indicates that individual claims by experts must be critically evaluated, and not taken as fact merely because of the rank of the claimant.
LikeLiked by 1 person
test
LikeLike
Is there a word limit for comments?
LikeLike
There was a wierd login thing, and when I refresh I don’t see the comment written anywhere. Thankfully, I copied it to clipboard. Let’s see if it lets me this time, sorry if I accidentally cause a duplicate. I suspect my issues in posting are due to a word limit, so I’m breaking things up.
My formatting is a little wierd. Basically, I have some stuff written down and I have a big ol’ list of sources and I give each one a unique source number and then cite the source numbers instead of an article title or a link for the sake of brevity; to save myself time I’ll just paste the entire source list including the things the following stuff doesn’t cite. One thing I would like to note on the bias thing is that it would have been relevent for you to bring up the finding included in your anti-white left article that leftists would support the suppression of evidence of the inferiority of one of their protected groups. Another useful thing to bring up is kirkegaard’s list of examples of politically correct reverse publication bias:
https://emilkirkegaard.dk/en/?p=8629
Anyways, I have some stuff to contribute. A bit of it is from Ryan’s videos on the peer review process, but he never made any sort of actual article so I thought I should include it anyways.
.
What Peer Review Encourages:
Quoting from Source 4, replacing references with source numbers:
.
“
.
Reviewers appear to base their judgments on cues that have only a weak relation to quality. Such cues include (1) statistical significance, (2) large sample sizes, (3) complex procedures, and (4) obscure writing. Researchers might use these cues to gain acceptance of marginal papers [Source 34].
Although it typically has little relationship to whether the findings are important, correct, or useful, statistical significance plays a strong role in publication decisions as shown by studies in management, psychology, and medicine [Sources 35, 38, 39, 40, & 41]. The case against statistical significance is summarized for psychologists by [Source 42] and for economists by [Source 43]. If the purpose is to give readers an idea of the uncertainty associated with a finding, confidence intervals would be more appropriate than significance tests.
[Source 44] conducted an experiment to determine whether reviewers place too much emphasis on statistical significance. They prepared three versions of a bogus manuscript where identical findings differed by the level of statistical significance. The reviewers recommended rejection of the paper with nonsignificant findings three times as often as 7 the ones with significant findings. Interestingly, they based their decision to reject on the design of the study, but the design was the same for all versions.
Using significance tests in publication decisions will lead to a bias in what is published. As [Source 45] noted, when studies with nonsignificant results are not published, researchers may continue to study that issue until, by chance, a significant result occurs. This problem still exists [Source 41].
Large sample sizes are used inappropriately. Sometimes they are unnecessary. For example, reviewers often confuse expert opinion studies with surveys of attitudes and intentions. While attitudes and intentions surveys might require a sample of more than a thousand individuals, expert opinion studies, which ask how others would respond, require only 5 to 20 experts [Source 46, p. 96]. Even when sample size is relevant, it is likely to be given too much weight. For example, Source 47, in a study of election polls for the U.S. presidency, concluded that the sample size of the surveys was loosely related to their accuracy.
Complex procedures serve as a favorable cue for reviewers. One wonders whether simpler procedures would suffice. For example, in the field of forecasting, where it is possible to assess the effectiveness of alternate methods, complex procedures seldom help and they sometimes harm accuracy [Source 46]. Nevertheless, papers with complex procedures dominate the forecasting literature. Obscure writing impresses academics. I asked professors to evaluate selections from conclusions from four published papers [Source 48]. For each paper, they were randomly assigned either a complex version (using big words and long sentences, but holding content constant), the original text, or a simpler version. The professors gave higher ratings to authors of the most obscure passages. Apparently, such writing, being difficult to understand, leads the reader to conclude that the writer must be very intelligent. Obscure writing also makes it difficult for 8 reviewers and readers to find errors and to assess importance. To advance their careers, then, researchers who do not have something important to say can obfuscate.
.
”
.
As you can see, peer review is quite a stringent, laborious process. Can you believe that reviewers are able to do all that work in between just two and six hours? It’s true [Source 49, 50, 51, & 52]. However, some do not realize how quick the process is because reviewers wait for months before reviewing. The wait to get a paper published can be even longer than this for many authors because a rejection doesn’t mean that you have to delete your paper, it just means that if your heart is set on publishing, you just have to keep on going through journal after journal while never being allowed to be reviewed by multiple journals at the same time.
Source 53 found that 85% of the papers rejected by the Journal of Clinical Investigation were eventually published elsewhere, and the majority of these were either not changed or changed in only minor ways. Source 4 reports that Source 54 obtained similar results for papers rejected by the British Medical Journal, but I could not find a text of Source 54, just the citation. Source 55 reached a similar conclusion for papers in the social sciences. Source 56, in a study of papers rejected by the American Political Science Review, concluded that of the 263 papers that were then submitted to another journal, 43% contained no revisions based upon the APSR reviews.
LikeLiked by 1 person
Publish Or Perish:
Focus groups of scientists report career pressures to publish high volumes of papers with positive results that confirm orthodoxy in high impact journals [74]. Universities want to be able to say that all of their professors publish in all of the best journals. Many universities do not focus on teaching ability when they hire new faculty and simply look at the publications list [75]. Tragically, in some countries, the number of publications in journals with high impact factors condition the allocation of government funding for entire institutions [76].
For many, it is publish or perish.
At the time of its inception in 1955, Garfield, the inventor of the impact factor did not imagine that some day his tool would become a controversial and abusive measure. Originally it was just meant to be a tool to help librarians choose what material to order for their libraries in order to satisfy the most researchers by measuring the popularity of research [78], little did he imagine how much the scope of its use would expand.
Just as quantitative evidence repeatedly shows that financial interests can influence the outcome of biomedical research [79 & 80], publish or perish culture affects all manner of research behavior including salami slicing to publish the least publishable unit sized papers [81]. In 2006 alone, an estimated 1.3 million papers were published alongside a large rise in the number of available scientific journals from 16,000 in 2001 to 23,750 by 2006 [82]. The total number of journal articles is estimated to have passed 50 million in 2009 [83].
Journal rank is most commonly assessed using Thomson Reuters’ Impact Factor which has been shown to correspond well with subjective ratings of journal quality and rank [84, 85, 86 & 87]. However, despite the perceived prestige and the importance placed on the impact factor, all evidence seems to suggest that the perverse incentives actually cause papers published in high impact factor to be more unreliable on average than papers published in “worse” journals.
Journal rank is predictive of the incidence of fraud and misconduct in retracted publications as opposed to other reasons for retraction [133 & 89], and larger journals have more retractions [13]. The fraction of retractions due to misconduct has risen sharper than the overall retraction rate and now the majority of all retractions are due to misconduct [89 & 90]. This is consistent with focus groups which suggest that the need to compete in academia is a threat to scientific integrity [74], with the fact that those found to be guilty of scientific misconduct often invoke excessive pressures to produce as partial justification for their actions [91], and with surveys suggesting that competitive research environments decrease the likelihood to follow scientific ideals [92] and and increase the likelihood to witness scientific misconduct [93].
The coefficient of determination (R^2) for the relationship between journal rank and retraction rate is .77 [89]. It may be possible that this relationship is too strong to be determined exclusively by increased fraud in high ranking journals. Retracted papers are such a low percentage of papers that it is possible that the number of retractable papers is higher than the number of retractable papers which have been retracted, and that detection problems partially contribute to the strength of this relationship. Perhaps the increased readership in high ranking journals make any given error more likely to be found. It isn’t however so far possible to measure the strength of such an effect. In addition, keep in mind that such an effect would just be a snowball effect of journal respect rather than an effect of higher journal quality.
So, with retractions being such a small percentage of publications, what can we say about the effect of impact factor on the rest of publications?
When aiming to compare the quality of papers in larger journals to papers in smaller ones, some aspects of an article’s quality can be rather subjective things to analyze. This is supposed to be judged by the peer review process itself, but peer review is the very thing under scrutiny. What we can do however is look at traits like statistical power, and if one journal repeatedly has underpowered studies, we can take that as a proxy for other qualities.
Source 5 has many such proxies, statistical power being one of them. A sample of 650 neuroscience studies showed no relation between statistical power and journal impact factor
[Source 5 – Figure 3, data from Source 6].
Another indicator was crystallographic quality (the quality of computer models derived from crystallographic work) This lets us see how often journals deviate from known atomic distances, and what is found, is that higher impact journals have worse crystallographic work, meaning that their molecular models have more errors than the lower impact journals [Source 5 – Figure 1, data from Source 8].
You can say that this is a rather limited indicator of journal quality, fair enough, and to the extent that this is an indicator of other qualities is unknown, but it’s another objective trait to add to the list.
Figure 5 looks at the rate in which papers from various journals get gene symbols and SNPs wrong. Taking nature, a journal famous enough for me to know about it as an example, about ⅓ of all genetics papers mislabel some bit of genetic data somewhere in the paper. No relationship
was found between impact factor and error rate [Source 5 – Figure 5, data from Source 10].
Not that a mislabeled piece of data here and there is the biggest deal ever, but it’s another small objective indicator of quality.
Figure 4 looks at how often studies have randomized control trials, and how many of them had double blind results in experiments on animals (Practices that exist to attempt to limit the influence of author bias on a study’s results). What was found, is that higher impact journals had roughly the same rate of blinding as lower impact journals, but less randomization than lower
impact ones [Source 5 – Figure 4, data from Source 11].
Figure 6 found a significant correlation between journal impact factor and the miscalculation of p-values [Source 5 – Figure 6, data from Source 12].
The percentage of papers with at least 1 miscalculated p-values at least somewhere in the paper was around 18% in the highest impact journals and around 12% in the lowest impact ones. Higher impact journals had about 3% of p-values miscalculated while lower impact one had 1.5% of p-values miscalculated. If a result isn’t true, there’s a small chance that a random collection of data would appear in such a way to make it look like it were true. A p-value calculates the chance of the result to look the way that it does were the null hypothesis to be true. This is a small thing, but it’s another objective sign that larger journals don’t necessarily publish better papers.
Figure 2 looks at the effect size in gene association studies divided by the pooled effect size estimate derived from a meta analysis. A higher number means that a study’s effect size deviates from the results that most papers find than a study with a lower number, and the larger the circle, the larger the sample population that was used. What this shows, is that higher impact factor journals have smaller sample sizes, with bigger, flashier, more exciting results which aren’t
replicated [Source 5 – Figure 2, data from Source 9].
The efficacy of high impact factor journals should not be a surprise given the substance of what impact factor actually is and how it is calculated [6].
LikeLike
Bias:
Source 5 – Figure 2 was evidence that journal rank / publish or perish culture is tied to the decline effect caused by publication bias [6]. The decline effect is basically the phenomena that the first paper which observes an effect has a large effect size, but subsequent papers that attempt to replicate the first either fail to replicate it or come up with much lower effect sizes. The usual pattern is of the initial study being published in a high impact journal followed by smaller journals showing that the effect fails replication. One particular case showcasing this pattern in the decline effect is Source 94. Source 77 makes a good introduction to the evidence on bias, to quote from it (keeping the sources but replacing source numbers):
.
“
In many fields of research, papers are more likely to be published [95-page.371,96,97,& 98], to be cited by colleagues [99,101,& 102] and to be accepted by high-profile journals [103] if they report results that are ‘‘positive’’ – term which in this paper will indicate all results that support the experimental hypothesis against an alternative or a ‘‘null’’ hypothesis of no effect, using or not using tests of statistical significance. Words like ‘‘positive’’, ‘‘significant’’, ‘‘negative’’ or ‘‘null’’ are common scientific jargon, but are obviously misleading, because all results are equally relevant to science, as long as they have been produced by sound logic and methods [104,& 105]. Yet, literature surveys and meta-analyses have extensively documented an excess of positive and/or statistically significant results in fields and subfields of, for example, biomedicine [106], biology [107], ecology and evolution [108], psychology [109], economics [110], sociology [112]. Many factors contribute to this publication bias against negative results, which is rooted in the psychology and sociology of science. Like all human beings, scientists are confirmation biased (i.e. tend to select information that supports their hypotheses about the world) [113,114,& 115], and they are far from indifferent to the outcome of their own research: positive results make them happy and negative ones disappointed [116]. This bias is likely to be reinforced by a positive feedback loop from the scientific community. Since papers reporting positive results attract more interest and are cited more often, journal editors and peer reviewers might tend to favour them, which will further increase the desirability of a positive outcome to researchers, particularly if their careers are evaluated by counting the number of papers listed in their CVs and the impact factor of the journals they are published in. Confronted with a ‘‘negative’’ result, therefore, a scientist might be tempted to either not spend time publishing it (what is often called the ‘‘file-drawer effect’’, because negative papers are imagined to lie in scientists’ drawers) or to turn it somehow into a positive result. This can be done by re-formulating the hypothesis (sometimes referred to as HARKing: Hypothesizing After the Results are Known [118]), by selecting the results to be published [119], by tweaking data or analyses to ‘‘improve’’ the outcome, or by willingly and consciously falsifying them [120]. Data PLoS ONE | http://www.plosone.org 1 April 2010 | Volume 5 | Issue 4 | e10271 fabrication and falsification are probably rare, but other questionable research practices might be relatively common [121]. Quantitative studies have repeatedly shown that financial interests can influence the outcome of biomedical research [79,& 80] but they appear to have neglected the much more widespread conflict of interest created by scientists’ need to publish.
”
.
Source 77 provides direct evidence that publish or perish is tied to publication bias. It looks at U.S. states by how many papers are published in each state and how often positive results are achieved. More productive states have more publication bias. Controlling for per capita research expenditure or a few other variables strengthens the relationship.
LikeLike
Here’s the source list that the source number in text citations link to: Very bottom of the google doc:
https://docs.google.com/document/d/1-C9BHXj44a7MDHQH9WrWaVee9TCB-lKvlv36rnv-gQs/edit?usp=sharing
I aim to make this google doc cover every single argument needed for hereditarianism and a few other topics. Here I just copy/pasted the stuff on this topic that I had which wasn’t covered by you. I would just re-paste the source list, but I think the source list is what’s preventing me from posting.
LikeLike
Nice! I have a doc that is somewhat similar that I simply use as my info archive — AFAIK, it is the largest of its kind by far with almost 13,000 entries covering hbd and political-related topics and the sort.
If you want to collab somehow or something, let me know where I can contact you!
LikeLike
wehrkatzer@gmail.com
LikeLike
Other account was me phone posting, wehrkatzer@gmail.com is indeed where you can contact me. We can set up something a little better than email for regular exchange if you’d like.
LikeLike
so uh… Where is one to find this AFAIK thing?
LikeLike
The worst part is that except for a few disciplines, the role of experts is not to make predictions and that they should refrain from them. The goal of science is to explain things and prescribe solutions, not predict. Experts should refrain from making predictions.
One thing that the article does not talk about: If you have to remain critical of the experts, you have to be even more suspicious of the academics speaking on areas that do not concern their specialty. It is not uncommon to see academics speaking out on subjects where they have no competence. The concern is that most people believe that they are experts in the discipline because they see a university title.
In France, a political scientist, Raul Magni-Berton has shown that if there was a distance between what experts and the public think, this distance was even greater between experts and academics. for example, academics are overwhelmingly anti-capitalist. Except the economists who favor capitalism. He gives other examples.
It reminds me of IQ. Most academics think IQ is pseudo science except intelligence experts.
In reality, an academic speaking on a subject that is not his or her specialty is more likely to say anything than an ordinary person.
Academics are hypocrites. They place great value on academic advice in their own disciplines, but don’t care much about the opinion of academic specialists on other subjects.
Beware of experts but even more of academics speaking on a subject that is not their specialty.
When I see an academic speaking the first thing I do is check if it’s his specialty
A good article on the limits of science and the dangers of scientism: https://medium.com/swlh/against-scientism-10b82d8bd5b1
(The danger is mainly the misuse of science and not science as such. On certain subjects, we do not have the capacity to have certainties. It is dangerous to present studies which do not bring no certainties like scientific truths).
I find it unfortunate that this article does not speak more about the problem of political bias which is a serious problem in the social sciences. In the hard sciences, because of the subject studied, political bias is not a problem. But in social sciences, where the subject studied is politically sensitive, this is a real problem.
Human subjects are more likely to arouse the ideological preconceptions of those who study them. For this reason, and for others, the social sciences are probably more difficult, at least in this sense, than the natural sciences.
LikeLike
Pingback: The Rise and Fall of Science | Ideas and Data
Pingback: The Rise and Fall of Science - GistTree
Pingback: How Bad Has the US Economy Become for Regular People? (1970 – 2020) | Ideas and Data
Pingback: Best Political Content Creators – Unraveler
Reblogged this on Calculus of Decay .
LikeLike
Pingback: 对学术专家的信任 - 偏执的码农